
Jedním z argumentů, který se lidé pokoušejí uvést jako důkaz „virů“, je existence „virových“ genomů. Věří tomu, že pokud lze genom sekvenovat z nepurifikované směsi buněčné kultury, ve které se předpokládá existence „viru“, je to podle nich dostatečný důkaz toho, že „virus“ skutečně fyzicky existuje. Pomineme-li ironii tvrzení, že náhodné báze A, C, G, T v počítačové databázi lze nějakým způsobem použít jako důkaz fyzické existence neviditelné entity, existuje mnoho důvodů, proč o spolehlivosti a přesnosti genomů pochybovat. Mezi ně, kromě jiného, patří spoléhání se na nepřesné referenční genomy, neschopnost replikovat výsledky, četné technologické překážky závisející na použité technice, vliv zkreslení, chyb a artefaktů, neošetřené databáze atd. Je naprosto směšné věřit, že tyto nereprodukovatelné sekvence z nepurifikované směsi buněčné kultury, náchylné k chybám, lze použít jako NEPŘÍMÝ důkaz „viru“, když PŘÍMÝ důkaz, tj. purifikované/izolované částice odebrané přímo od nemocných lidí, u kterých byla přirozenou cestou prokázána patogenita, musí být teprve vědecky prokázán. Níže jsou hlavní body z jednoho článku a jedné přehledové studie, ukazující mnohé z těchto nedostatků:
PŘESNOST SEKVENOVÁNÍ LIDSKÉ DNA
„Ale JAK PŘESNÉ JE SEKVENOVÁNÍ DNA A JEHO TECHNIKY UKLÁDÁNÍ DAT? Jaký vliv mají tyto NEPŘESNOSTI NA GENOMIKU a její použití ve farmakogenetice?
V průběhu Projektu lidského genomu existovaly RŮZNÉ ÚROVNĚ PŘESNOSTI, o které výzkumné instituce usilovaly. V roce 2000 byla zveřejněna první pracovní verze genomu s MÍROU CHYBOVOSTI JEDNÉ CHYBY NA KAŽDÝCH 1 000 PÁRŮ BÁZÍ. V roce 2003 oficiální výsledky uváděly MÍRU CHYBOVOSTI JEDNÉ CHYBY NA KAŽDÝCH 10 000 PÁRŮ BÁZÍ. Abyste dosáhli této úrovně přesnosti, je v současné době zapotřebí, abyste prošli a sekvenovali DNA celkem desetkrát. Mezinárodní standard přesnosti (známý jako Bermudské standardy) je v současné době udržován na jedné chybě na 10 000 párů bází pro celou souvislou sekvenci – DNA JE SEKVENOVÁNA PO ČÁSTECH A MEZI TĚMITO RŮZNÝMI ČÁSTMI ČASTO EXISTUJÍ MEZERY. Bez ohledu na to, jak přesný se tento proces sekvenování MŮŽE ZDÁT, při sekvenování celého lidského genomu TAKTO VZNIKNE CELKEM CCA 300 000 CHYB PÁROVÝCH BÁZÍ.
Jak významná však míra chybovosti 0,0001 % je? Projekt lidského genomu upozornil na význam jednonukleotidových polymorfismů (SNP). Jednonukleotidové polymorfismy jsou PŘIROZENÉ SEKVENAČNÍ VARIACE DNA v jediném nukleotidu (A, T, C nebo G), které se vyskytují na každých 100 až 300 párů bází. VARIACE ZPŮSOBENÉ JEDNONUKLEOTIDOVÝM POLYMORFISMEM MOHOU MÍT DRAMATICKÝ VLIV NA TO, JAK LIDÉ REAGUJÍ ODLIŠNĚ NA VĚCI, JAKO JSOU LÉKY, VAKCÍNY NEBO NEMOCI. Společnosti, jako je 23andMe, které sekvenují DNA, však určitě budou kvůli PŘIROZENÝM A PŘÍPUSTNÝM CHYBÁM SEKVENOVAT NĚKTERÉ JEDNONUKLEOTIDOVÉ POLYMORFISMY NEPŘESNĚ. Problém je v tom, že společnosti jako 23andMe počítají s tím, že výsledky sekvenování DNA použijí k poskytování lékařských rad pacientům a jejich lékařům, aby mohli předepisovat přesnější dávkování léků. JAK PŘESNÁ VŠAK MŮŽE TATO LÉKAŘSKÁ RADA, S VÍCE NEŽ 300 000 CHYBAMI PÁRŮ BÁZÍ, BÝT? Pokud jsou schopnosti a omezení lidského těla citlivé až na úroveň jednotlivých nukleotidů (jako v případě jednonukleotidového polymorfismu), MŮŽE BÝT SEKVENOVÁNÍ LIDSKÉHO GENOMU DOSTATEČNĚ SPOLEHLIVÉ, ABY SLOUŽILO SVÉMU ÚČELU JAKO ZDROJ PERSONALIZOVANÝCH LÉKAŘSKÝCH INFORMACÍ ZCELA ZÁVISLÝCH NA LIDSKÉ DNA?“
https://cs.stanford.edu/…/2010-11/Genomics/accuracy.html
Shrnutí 1. části:
- výzkumné instituce usilovaly o RŮZNÉ ÚROVNĚ PŘESNOSTI
- v roce 2000 byla zveřejněna první pracovní verze genomu s MÍROU CHYBOVOSTI JEDNÉ CHYBY NA KAŽDÝCH 1 000 PÁRŮ BÁZÍ
- v roce 2003 oficiální výsledky uváděly MÍRU CHYBOVOSTI JEDNÉ CHYBY NA KAŽDÝCH 10 000 PÁRŮ BÁZÍ
- DNA je sekvenována po částech a MEZI TĚMITO RŮZNÝMI ČÁSTMI ČASTO EXISTUJÍ MEZERY
- takto vznikne celkem cca 300 000 CHYB PÁROVÝCH BÁZÍ
- jednonukleotidové polymorfismy jsou PŘIROZENÉ SEKVENAČNÍ VARIACE DNA v jediném nukleotidu (A, T, C nebo G), které se vyskytují na každých 100 až 300 párů bází
- VARIACE ZPŮSOBENÉ JEDNONUKLEOTIDOVÝM POLYMORFISMEM MOHOU MÍT DRAMATICKÝ VLIV na to, jak lidé reagují odlišně na věci, jako jsou léky, vakcíny nebo nemoci
- společnosti, jako je 23andMe, které sekvenují DNA, budou kvůli PŘIROZENÝM A PŘÍPUSTNÝM CHYBÁM určitě sekvenovat některé jednonukleotidové polymorfismy NEPŘESNĚ
- JAK PŘESNÁ může tato lékařská rada, s více než 300 000 chybami párů bází, být?
- může být sekvenování lidského genomu DOSTATEČNĚ SPOLEHLIVÉ na to, aby sloužilo svému účelu jako zdroj personalizovaných lékařských informací zcela závislých na lidské DNA?
Z přehledové studie z roku 2019:
SABOTUJE VAŠE EXPERIMENTY SPOLÉHÁNÍ SE NA NEPŘESNOU SEKVENCI GENOMU?
„Nové technologie a pokroky v algoritmech však NEZARUČUJÍ BEZCHYBNÉ GENOMOVÉ SEKVENCE ANI ANOTACE. ZKRESLENÍ, CHYBY A ARTEFAKTY se mohou vloudit v jakékoli fázi procesu od přípravy knihovny sekvencí až po anotaci.“
„U VŠECH SEKVENCÍ GENOMU SE VYSKYTUJÍ ‚PROBLÉMY‘
Existuje MNOHO FAKTORŮ, které mohou ovlivnit konečnou sekvenci genomu a anotaci, a obě BY MĚLY BÝT POVAŽOVÁNY ZA PRODUKTY ‚VE STÁDIU VÝVOJE‘.“
„Jaký je původ vzorku použitého k vytvoření sekvence genomu?
NA PŮVODU ZÁLEŽÍ. Pocházel vzorek z klonu, smíšené populace (běžné u mikrobů) nebo případně z hybridu? Rozdíly mezi jednotlivci mohou tvořit jednonukleotidové polymorfismy (SNP), ale často zahrnují také INZERCE NEBO DELECE (INDELY) RŮZNÝCH VELIKOSTÍ, VARIABILITU POČTU KOPIÍ (CNV) A DOKONCE I MALÁ PŘEUSPOŘÁDÁNÍ. U hybridů mohou být dramatické rozdíly mezi ortologními chromozomy [1]. Sekvence genomu odvozené z heterogenní populace, zvláště pokud se v ní vyskytuje variabilita počtu kopií, KOMPLIKUJÍ SESTAVENÍ GENOMU a VYTVOŘENÁ SEKVENCE JE ČASTO KOMPOZITEM hlavních alel přítomných v sekvenovaném vzorku. Sekvence genomu odvozené z klonálních laboratorních kmenů se často snáze sestavují, ALE PRO CIRKULUJÍCÍ KMENY DIVOKÉHO TYPU NEMUSÍ BÝT SKUTEČNĚ REPREZENTATIVNÍ, protože jsou na kulturu adaptovány a pokud se množí delší dobu, MOHOU ZTRATIT GENY NEBO NAHROMADIT MUTACE [2].“
„Má genom problematické vlastnosti?
Některé sekvence genomu lze fyzicky obtížně sekvenovat Z DŮVODU EXTRÉMNÍHO ZKRESLENÍ NUKLEOTIDŮ.“
„Dlouhé homopolymerní úseky jakékoli báze jsou u některých sekvenačních technologií ZVLÁŠTĚ PROBLEMATICKÉ [4] a MOHOU VÉST K NESPRÁVNÉMU POČTU NUKLEOTIDŮ, což má za následek posun čtecího rámce, pokud je sekvence kódující.“
„Pokud sekvence genomu OBSAHUJE ČETNÉ REPETITIVNÍ SEKVENCE, retrotranspozony nebo mobilní elementy nebo velké, velmi podobné genové rodiny, SESTAVENÍ GENOMU TÍM BUDE OVLIVNĚNO, zvláště pokud byly ke čtení použity jen krátké sekvence.“
„Repetitivní sekvence jsou pro většinu algoritmů pro sestavení genomu OBROVSKÝM PROBLÉMEM.“
„MÉNĚ PŘESNÉ čtení dlouhých úseků s nízkou hloubkou pokrytí lze použít jako rámec, na kterém lze mapovat kratší sekvence.“
„Existuje snadný způsob, jak posoudit kvalitu sestavení genomu u daného organismu. Mapujte čtení z projektu sekvenování zpět do SESTAVENÉ SEKVENCE GENOMU a podívejte se na něj.“
„Sestava referenčního genomu Toxoplasma gondii ME49 (parazit z podkmene výtrusovci – Apicomplexa) obsahuje několik „collapsed regions“, které se liší podle kmene [8]. I PŘES VYSOKOU KVALITU TÉTO GENOMOVÉ SEKVENCE A JEJÍ SHODĚ S GENETICKÝMI MAPAMI STÁLE EXISTUJÍ PROBLÉMY SOUVISEJÍCÍ S POČTEM CHROMOZOMŮ [13, 14].“
„SEKVENCE GENOMU, KTERÉ VYCHÁZELY Z KLONOVÁNÍ A BIOLOGICKÉ REPLIKACE, MAJÍ DALŠÍ PROBLÉMY, KTERÉ JE TŘEBA VZÍT V ÚVAHU. NĚKTERÉ SEKVENCE JEDNODUŠE NELZE KLONOVAT; pro organismus používaný ke klonování a replikaci jsou toxické, a proto BUDOU VE VYTVOŘENÉ SEKVENCI GENOMU CHYBĚT. Neklonovatelné sekvence často obsahují několik vybraných genů a heterochromatin. Opak je také pravdou: SEKVENCE DNA Z KLONOVACÍHO VEKTORU NEBO ORGANISMU, POUŽITÁ KE KONSTRUKCI KNIHOVNY, SE MŮŽE OBJEVIT V SESTAVENÉ SEKVENCI CÍLOVÉHO GENOMU.“
„VYSOCE VÝKONNÁ PŘÍPRAVA KNIHOVNY SEKVENOVÁNÍ NOVÉ GENERACE (NGS) HRAJE ZÁSADNÍ ROLI S OHLEDEM NA KVALITU PRODUKOVANÉ SEKVENCE GENOMU. Mnoho protokolů obsahuje amplifikační kroky, KTERÉ MOHOU ZPŮSOBIT ZKRESLENÍ VÝSLEDKŮ. Pro sekvenování genomu mohou být použity například jednotlivé buňky, ale prostřednictvím celogenomové amplifikace (WGA). Tento přístup je účinný, když je materiál omezený, ale proces amplifikace je zkreslený a k plné identifikaci a odstranění zkreslení amplifikace je zapotřebí několik různých reakcí celogenomové amplifikace (na různých buňkách nebo populacích podobných buněk) [15, 16]. JE TŘEBA POZNAMENAT, ŽE Z ČTENÍ ODESLANÝCH DO ARCHÍVŮ JE ZKRESLENÍ ZŘÍDKAKDY ODSTRANĚNO, takže je nutné vědět, zda byla celogenomová amplifikace použita.“
„Jaká sekvenační platforma byla použita?
RŮZNÉ SEKVENAČNÍ PLATFORMY MAJÍ RŮZNÉ SILNÉ A SLABÉ STRÁNKY [9] a nadále se rychle vyvíjejí a často se navzájem doplňují, pokud se uplatní několik různých přístupů. Sekvence genomu sestavené Sangerovou metodou budou mít dobrou kvalitu sekvence, ALE SESTAVENÁ SEKVENCE GENOMU BUDE OVLIVNĚNA VÝŠE ZMÍNĚNÝMI PROBLÉMY KNIHOVNY SEKVENCÍ. Sekvence genomu generované staršími systémy (např. 454 a Ion Torrent) BUDOU MÍT PROBLÉMY S CHYBNÝM ČTENÍM HOMOPOLYMERŮ. U novějších sekvencí genomu bude použita vysoce přesná technologie krátkého čtení Illumina, ALE SESTAVENÉ SEKVENCE, zvláště pokud obsahují opakující se úseky, BUDOU NEÚPLNÉ A BUDOU OBSAHOVAT MEZERY A CHYBNÉ SESTAVY, a to v případě, že nebyla použita hybridní sestava využívající technologie pro dlouhé čtení jako PacBio nebo Oxford Nanopore.
Jak byl genom sestaven?
Sekvenační sestavy jsou dvojího druhu: de novo (sestavené od nuly) a sestavené s pomocí referenčního genomu. DRUHÝ ZPŮSOB SE NORMÁLNĚ POUŽÍVÁ, POKUD JIŽ EXISTUJE ZAVEDENÝ REFERENČNÍ GENOM DANÉHO ORGANISMU A EXPERIMENTÁLNÍM CÍLEM JE URČIT JEHO VARIABILITU. NENÍ TO DOBRÝ POSTUP K DETEKCI PŘESKUPENÍ NEBO SYNTENICKÝCH ZLOMŮ, ale je ideální pro detekci jednonukleotidových polymorfismů, některých indelů a variability počtu kopií. POSTUP S POUŽITÍM REFERENČNÍHO GENOMU NEZJISTÍ VLASTNOSTI GENOMU, KTERÉ V REFERENČNÍM GENOMU NEJSOU, COŽ JE VÝZNAMNÁ NEVÝHODA TÉTO METODY. Vzhledem k velkému objemu populačních studií, zaměřených na jednonukleotidové polymorfismy, VĚTŠINA ÚDAJŮ O SEKVENCÍCH GENOMŮ BOHUŽEL ZŮSTÁVÁ VE FORMĚ NESESTAVENÝCH SOUBORŮ ČTENÍ.
SEKVENACE DE NOVO JE JEDINOU MOŽNOSTÍ PRO SESTAVENÍ PRVNÍ GENOMOVÉ SEKVENCE ORGANISMU, a pokud je to možné, měla by být používána k objevování nových vlastností. V případě sekvencí genomu u eukaryot, zvláště když karyotyp NENÍ ZNÁM A FYZICKÉ MAPY NEEXISTUJÍ, ČTENÍ LZE SESTAVIT POUZE ČÁSTEČNĚ do kontinuálních sekvencí, ‚kontigů‘ nebo superkontigů, OBSAHUJÍCÍCH MEZERY. Kontigy často obsahují sekvence, které jsou poměrně jedinečné, protože REPETITIVNÍ SEKVENCE JSOU V SESTAVĚ DE NOVO ČASTO ‚MASKOVÁNY‘ kvůli problémům, které způsobují. Výsledkem je, že kontigy často končí nebo jsou od sebe odděleny CHYBĚJÍCÍMI OPAKUJÍCÍMI SE OBLASTMI, KTERÉ NEBYLY VYUŽITY (byly např. maskovány) NEBO JE NEBYLO MOŽNÉ BĚHEM SESTAVOVÁNÍ VYŘEŠIT. S VARIACEMI NALEZENÝMI NA KONCÍCH KONTIGŮ JE TŘEBA ZACHÁZET OPATRNĚ. Mezery mezi kontigy, které byly uspořádány a orientovány do superkontigů, jsou často označeny přesně 100 ‚N‘ k označení mezery neznámé velikosti. V některých případech jsou sestaveny superkontigy reprezentující celé chromozomy, ale i ty často obsahují četné mezery nebo nejednoznačné báze. NĚKTERÉ SYSTÉMY TAKÉ VYTVÁŘEJÍ SUPERKONTIG, KTERÝ SPOJUJE DOHROMADY VŠECHNY ‚ZBYLÉ‘ KONTIGY. DEJTE SI POZOR NA SUPERKONTIG, často nazývaný ‚superkontig 0‘, PROTOŽE POŘADÍ A ORIENTACE TĚCHTO KONTIGŮ SE JEJICH BIOLOGICKÉMU UMÍSTĚNÍ NIJAK NEPODOBAJÍ; je to jednoduše vyhovující mechanismus k zajištění toho, aby byly k používání nebo prohledávání sekvence genomu dostupné všechny kontigy.“
„Pokud je sekvence referenčního genomu již k dispozici, můžete použít nesestavená čtení k detekci variant sekvencí a variability počtu kopií mnohem rychleji bez sestavení.“
„KAŽDÝ ZPŮSOB SESTAVOVÁNÍ SEKVENCÍ OBSAHUJE ŘADU PROBLÉMŮ a většina projektů sekvenování genomu produkuje soubor zbylých čtení a kontigů, KTERÉ NEJSOU K SESTAVENÍ POUŽITY. V některých případech MOHOU BÝT TATO ČTENÍ IDENTIFIKOVÁNA JAKO KONTAMINACE, NEOČEKÁVANÝ SYMBIONT NEBO SEKVENCE GENOMU ORGANEL. V ostatních případech JSOU PŘEBÝVAJÍCÍ ÚSEKY INDIKÁTOREM KONKRÉTNÍCH DRUHŮ CHYB PŘI SESTAVOVÁNÍ NEBO NEOČEKÁVANÝCH VARIACÍ SEKVENCE GENOMU, NAPŘ. VARIABILITY POČTU KOPIÍ NEBO VYSOKÉ ÚROVNĚ HETEROZYGOTNOSTI MEZI ALELAMI (zejména pokud byla sekvenována populace, nikoli jedinec).“
„Byla sekvence genomu ‚opravena‘ a pokud ano, jak?
ČTENÍ DLOUHÝCH SEKVENCÍ, KTERÁ JSOU NÁCHYLNÁ K CHYBÁM, lze před SESTAVENÍM OPRAVIT pomocí ‚proovread‘ [21]. OPRAVA PŘED SESTAVENÍM GENOMU MŮŽE SESTAVENÍ USNADNIT, KDYŽ JE CHYBOVOST VYSOKÁ, např. u čtení s nízkou hloubkou pokrytí PacBio. SESTAVENÉ SEKVENCE GENOMU LZE TAKÉ ‚VYLEŠTIT‘. Leštění (polishing) zahrnuje opravu bází a populárním nástrojem je ICORN2 [22]. Leštění se provádí pomocí vysoce přesných čtení Illumina mapovaných zpět proti konečné sestavě genomu. Korekce čtení a leštění jsou užitečné a doporučené kroky, ale JSOU VELMI ZÁVISLÉ NA VÝKONNOSTI ALIGNERU a koncový uživatel si musí být vědom toho, že OPRAVENÉ A VYLEŠTĚNÉ SEKVENCE BUDOU PŘEDSTAVOVAT NEJHOJNĚJŠÍ ALELY PŘÍTOMNÉ VE ČTENÍCH. Jinými slovy, ISOFORMY A VZÁCNÉ VARIANTY REPETITIVNÍCH SEKVENCÍ BUDOU ‚OPRAVENY‘, tj. PŘEPSÁNY PŘI KONEČNÉM SESTAVOVÁNÍ HOJNĚJŠÍMI SEKVENAČNÍMI VARIANTAMI.“
„GENOVÉ PREDIKCE JSOU ZÁVISLÉ NA SESTAVENÍ GENOMU, COŽ ZNAMENÁ, ŽE POKUD DANÁ OBLAST CHYBÍ, NELZE JI ANOTOVAT. Podobně, pokud je OBLAST ŠPATNĚ SESTAVENÁ NEBO CHYBÍ V SEKVENCI REFERENČNÍHO GENOMU POUŽITÉHO PRO ORTOLOGY, MŮŽE SE STÁT, ŽE BUDE CHYBĚT V SEKVENCI GENOMU, KTERÁ JE ANOTOVÁNA. Dobrým příkladem je Cryptosporidium. Sekvence genomu pro C. parvum byla zveřejněna v roce 2004 s nejmodernějším způsobem sestavení a anotace v té době [27]. Tato sekvence genomu byla použita jako referenční sekvence pro několik dalších kmenů a druhů Cryptosporidium [28, 29]. Tato praxe může být nebezpečná, protože jedním z rysů genomu, který usnadňuje speciaci, je přeskupení genomu, které ovlivňuje párování chromozomů během reprodukce. VZHLEDEM K TOMU, ŽE U MNOHA PATOGENŮ NEEXISTUJÍ GENETICKÉ SYSTÉMY, KTERÉ MOHOU BÝT POUŽITY K VYTVOŘENÍ FYZICKÉ MAPY, je referenční mapování užitečné, ALE JE SNADNÉ ZAPOMENOUT NA PŮVOD SESTAV GENOMOVÝCH SEKVENCÍ A ANOTACÍ VYTVOŘENÝCH NEBO ŠÍŘENÝCH TÍMTO ZPŮSOBEM, PROTO JE PŘI POUŽÍVÁNÍ SESTAV MAPOVANÝCH PODLE REFERENČNÍHO GENOMU JAKO ZÁKLADU PRO EXPERIMENTY POTŘEBA POSTUPOVAT OPATRNĚ.“
„Gen je anotován jako jedna kopie, je to tak?
Další kopie genů mohou zmařit experimenty určené k zaměření, klonování, odstranění nebo modifikaci konkrétního genu. Anotace může indikovat gen s jednou kopií, ale V ZÁVISLOSTI NA TECHNOLOGII, POUŽITÉ K VYTVOŘENÍ VAŠÍ GENOMOVÉ SEKVENCE, MOHOU BÝT TÉMĚŘ IDENTICKÉ KOPIE GENŮ SESTAVENY JAKO JEDEN GEN (k tomuto problému jsou nejčastěji náchylné sestavy s krátkým čtením) a mírně odlišní členové genové rodiny, zvláště pokud jsou v tandemových opakováních, SE ČASTO NESESTAVÍ A LZE JE NAJÍT VE ZBYLÝCH ČTENÍCH NEBO MALÝCH NESESTAVENÝCH KONTIZÍCH.“
„Anotace nepopisuje váš gen. Opravdu v genomu chybí?
NA ZÁKLADĚ STÁVAJÍCÍ ANOTACE JE SNADNÉ SE MYLNĚ DOMNÍVAT, že gen chybí. Geny se mohou ztratit a rozpadnout se nebo se změnit k nepoznání, ALE MOHOU TAKÉ CHYBĚT Z DŮVODU MEZERY V SESTAVENÉ SEKVENCI.“
„Nebo může určitá oblast v sestavě genomu chybět, tj. v porovnání se srovnávací sekvencí vznikne mezera. CHYBNÁ SESTAVENÍ A MEZERY MOHOU VYVOLÁVAT DOJEM CHYBĚJÍCÍCH GENŮ, ALE VE SKUTEČNOSTI V SESTAVĚ CHYBÍ, VYVINULY SE DO PSEUDO-GENŮ NEBO V NĚKTERÝCH PŘÍPADECH BYLY NAHRAZENY HORIZONTÁLNÍM PŘENOSEM GENŮ UMÍSTĚNÝCH JINDE V GENOMU.
MEZERY V SEKVENCÍCH GENOMU MAJÍ MNOHO DALŠÍCH DŮSLEDKŮ. Počet genů MŮŽE BÝT SNÍŽEN ve srovnání se skutečným počtem a ironií je, že počet genů MŮŽE BÝT TAKÉ ZVÝŠEN, protože část stejného genu lze nalézt na každé straně mezery, COŽ MÁ ZA NÁSLEDEK DVĚ DÍLČÍ PREDIKCE. Malé mezery v sestavě často vedou k posunům rámců v kódovacích sekvencích, což zase VEDE K UMĚLÉMU NÁRŮSTU POČTU PSEUDO-GENŮ, přičemž ve skutečnosti je na vině mezera v sestavě. Mezery mohou také indikovat umístění chybějící tandemové oblasti genů nebo opakujících se sekvencí, které NEBYLO MOŽNÉ SPRÁVNĚ SESTAVIT.“
„Mohu anotaci věřit?
Sekvence genomu některých organismů jsou kontinuálně upravovány vědeckou komunitou nebo odborníky a mají dobrou nedávnou anotaci genomu. ANOTÁTORY VŠAK NEMOHOU ANOTOVAT TO, CO NEEXISTUJE (např. MEZERY). Sekvence genomu eukaryot, zejména ze zvířecích, vektorových nebo rostlinných hostitelů, jsou složité, a dokonce i s kontinuálními úpravami je toho mnohem víc, co je třeba napravit a objevit, protože se objevují nové technologie sekvenování, sestavovací algoritmy a experimentální důkazy. Například NEPŘEKLÁDANÉ OBLASTI A NEKÓDUJÍCÍ RNA NEJSOU BĚŽNĚ ANOTOVÁNY. VŠECHNY GENOMOVÉ SEKVENCE A JEJICH ANOTACE JSOU ‚VE STÁDIU VÝVOJE‘ A JSOU STATICKÝMI PŘEDSTAVITELI JEDNOHO ČASOVÉHO OKAMŽIKU NEUSTÁLE SE VYVÍJEJÍCÍ MOLEKULY V RÁMCI GENETICKY ROZMANITÉ POPULACE.“
„Ovlivňuje anotace analýzy drah?
Ano. Studie zaměřené na objevování cílů pro působení léčiv často hledají gen, který se jeví jako pro danou dráhu nezbytný. Jakmile je gen objeven, je vyřazen a ke zděšení všech se zjistí, že nebyl nezbytný a organismus v přítomnosti léčiva přežívá. K tomu může dojít z mnoha důvodů, od schopnosti léčiva dosáhnout cíle až po možnost, že posouzení nezbytnosti bylo chybné. KE STEJNÉMU VÝSLEDKU MOHOU VÉST TAKÉ CHYBY V ANOTACI NEBO CHYBY V SESTAVĚ. Například gen nemusí být jedna kopie nebo se vyřazovací konstrukt choval podivně a cílil na příbuznou nebo dodatečnou genovou kopii cílové oblasti, což mělo za následek neobvyklé nebo těžko interpretovatelné výsledky. Případně VELKÝ PODÍL GENŮ NEZNÁMÉ FUNKCE (U NĚKTERÝCH ORGANISMŮ AŽ 40 %) KÓDUJE FUNKCE, KTERÉ UMOŽŇUJÍ ORGANISMU VYŘAZENÍ OBEJÍT. U tohoto důležitého typu genů je stále ještě zapotřebí udělat velký kus práce.“
„Kromě dlouhých čtení budou některé genomové sekvence vyžadovat další přístupy, jako je Hi-C (chromatin conformation capture) [35], metodologie chicagské knihovny [36] nebo optické mapování [37]. Skutečně obtížné genomové sekvence mohou být hexaploidní (jako pšenice), mohou mít obrovský počet superkontigů (jako Ixodes scapularis, který jich má více než 350 000), mohou obsahovat velmi podobné opakující se prvky (jako T. vaginalis) nebo mohou trpět extrémní heterogenitou a délkovými rozdíly mezi sesterskými chromozomy (jako u hybridního T. cruzi). NĚKTERÉ SEKVENCE GENOMU JIŽ BYLY TĚMITO NOVÝMI TECHNOLOGIEMI ‚OPRAVENY‘, ALE STÁLE JE ZAPOTŘEBÍ ZNAČNÉ PRÁCE, ABY BYLY TAK DOBRÉ, JAK JE TO JEN MOŽNÉ.“
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6742220/
Shrnutí 2. části:
- nové technologie a pokroky v algoritmech NEZARUČUJÍ bezchybné genomové sekvence ani anotace
- ZKRESLENÍ, CHYBY A ARTEFAKTY se mohou vloudit v jakékoli fázi procesu od přípravy knihovny sekvencí až po anotaci
- u VŠECH sekvencí genomu se vyskytují „PROBLÉMY“
- existuje MNOHO FAKTORŮ, které mohou ovlivnit konečnou genomovou sekvenci a anotaci, a obě BY MĚLY BÝT POVAŽOVÁNY ZA PRODUKTY „VE STÁDIU VÝVOJE“
- na PŮVODU genomu ZÁLEŽÍ – zda vzorek pocházel z klonu, smíšené populace (běžné u mikrobů) nebo případně z hybridu
- rozdíly mezi jednotlivci mohou tvořit jednonukleotidové polymorfismy (SNP), ale často zahrnují INZERCE NEBO DELECE (indely) RŮZNÝCH VELIKOSTÍ, VARIABILITU POČTU KOPIÍ (CNV), A DOKONCE I MALÁ PŘEUSPOŘÁDÁNÍ
- u hybridů mohou být DRAMATICKÉ ROZDÍLY mezi ortologními chromozomy
- sekvence genomu odvozené z heterogenní (obsahově různorodé) populace, zvláště pokud se v ní vyskytuje variabilita počtu kopií, KOMPLIKUJÍ SESTAVENÍ GENOMU a VYTVOŘENÁ SEKVENCE JE ČASTO KOMPOZITEM hlavních alel přítomných v sekvenovaném vzorku
- sekvence genomu odvozené z KLONÁLNÍCH laboratorních kmenů se často snáze sestavují, ALE PRO CIRKULUJÍCÍ KMENY DIVOKÉHO TYPU NEMUSÍ BÝT SKUTEČNĚ REPREZENTATIVNÍ, protože jsou na kulturu adaptovány a pokud se množí delší dobu, MOHOU ZTRATIT GENY NEBO NAHROMADIT MUTACE
- některé sekvence genomu lze fyzicky obtížně sekvenovat Z DŮVODU EXTRÉMNÍHO ZKRESLENÍ POČTU NUKLEOTIDŮ
- dlouhé homopolymerní úseky jakékoli báze jsou u některých sekvenačních technologií ZVLÁŠTĚ PROBLEMATICKÉ a MOHOU VÉST K NESPRÁVNÉMU POČTU NUKLEOTIDŮ, což má za následek posun čtecího rámce, pokud je sekvence kódující
- pokud sekvence genomu OBSAHUJE ČETNÉ REPETITIVNÍ SEKVENCE, retrotranspozony nebo mobilní elementy nebo velké, velmi podobné genové rodiny, SESTAVENÍ GENOMU TÍM BUDE OVLIVNĚNO, zvláště pokud byly ke čtení použity jen krátké sekvence
- repetitivní sekvence jsou pro většinu algoritmů pro sestavení genomu OBROVSKÝM PROBLÉMEM
- MÉNĚ PŘESNÉ čtení dlouhých úseků s nízkou hloubkou pokrytí lze POUŽÍT JAKO RÁMEC, na kterém lze mapovat kratší sekvence
- autoři uvádí, že existuje snadný způsob, jak posoudit kvalitu sestavení genomu u daného organismu, a to mapováním čtení z projektu sekvenování ZPĚT DO SESTAVENÉ SEKVENCE GENOMU a jeho kontrolou (co však dělat v případě, když je referenční genom nepřesný…?)
- názorný příklad: SESTAVA REFERENČNÍHO GENOMU Toxoplasma gondii ME49 (parazit z podkmene výtrusovci – Apicomplexa) obsahuje několik „collapsed regions“, které se LIŠÍ PODLE KMENE, A I PŘES VYSOKOU KVALITU této genomové sekvence a její shodě s genetickými mapami STÁLE EXISTUJÍ PROBLÉMY SOUVISEJÍCÍ S POČTEM CHROMOZOMŮ
- sekvence genomu, které vycházely z KLONOVÁNÍ A BIOLOGICKÉ REPLIKACE, MAJÍ DALŠÍ PROBLÉMY, které je třeba vzít v úvahu
- některé sekvence JEDNODUŠE NELZE KLONOVAT; pro organismus používaný ke klonování a replikaci jsou TOXICKÉ, a proto BUDOU VE VYTVOŘENÉ SEKVENCI GENOMU CHYBĚT
- sekvence DNA z klonovacího vektoru nebo organismu, použitá ke konstrukci knihovny, SE MŮŽE OBJEVIT V SESTAVENÉ SEKVENCI CÍLOVÉHO GENOMU
- jinými slovy, nežádoucí sekvence DNA z jiných organismů použitých pro klonování si našly cestu do nového genomu
- vysoce výkonná příprava knihovny sekvenování nové generace (NGS) hraje ZÁSADNÍ ROLI S OHLEDEM NA KVALITU PRODUKOVANÉ SEKVENCE GENOMU a mnoho protokolů obsahuje amplifikační kroky, KTERÉ MOHOU ZPŮSOBIT ZKRESLENÍ VÝSLEDKŮ
- je třeba poznamenat, že Z ČTENÍ ODESLANÝCH DO ARCHIVŮ JE ZKRESLENÍ ZŘÍDKAKDY ODSTRANĚNO
- různé sekvenační platformy mají různé silné a slabé stránky
- sekvence genomu sestavené Sangerovou metodou budou mít dobrou kvalitu sekvence, ALE SESTAVENÁ SEKVENCE GENOMU BUDE OVLIVNĚNA VÝŠE ZMÍNĚNÝMI PROBLÉMY KNIHOVNY SEKVENCÍ
- sekvence genomu generované staršími systémy (např. 454 a Ion Torrent) BUDOU MÍT PROBLÉMY S CHYBNÝM ČTENÍM HOMOPOLYMERŮ
- u novějších sekvencí genomu bude použita vysoce přesná technologie krátkého čtení Illumina, ALE SESTAVENÉ SEKVENCE, zvláště pokud obsahují opakující se úseky, BUDOU NEÚPLNÉ A BUDOU OBSAHOVAT MEZERY A CHYBNÉ SESTAVY
- REFERENČNÍ GENOMY se normálně používají, pokud JIŽ EXISTUJE ZAVEDENÝ REFERENČNÍ GENOM DANÉHO ORGANISMU a experimentálním cílem je určit jeho variabilitu
- Nevýhody referenčních genomů:
- Není to dobrý postup k detekci přeskupení nebo syntenických zlomů
- Postup s použitím referenčního genomu NEZJISTÍ VLASTNOSTI GENOMU, KTERÉ V REFERENČNÍM GENOMU NEJSOU, což je významná nevýhoda této metody
- vzhledem k velkému objemu populačních studií, zaměřených na jednonukleotidové polymorfismy, VĚTŠINA ÚDAJŮ O SEKVENCÍCH GENOMŮ BOHUŽEL ZŮSTÁVÁ VE FORMĚ NESESTAVENÝCH SOUBORŮ ČTENÍ
- sekvenace de novo JE JEDINOU MOŽNOSTÍ PRO SESTAVENÍ PRVNÍ GENOMOVÉ SEKVENCE ORGANISMU
- v případě sekvencí genomu u eukaryot, zvláště když karyotyp NENÍ ZNÁM A FYZICKÉ MAPY NEEXISTUJÍ, LZE ČTENÍ SESTAVIT POUZE ČÁSTEČNĚ do kontinuálních sekvencí, „kontigů“ nebo superkontigů, OBSAHUJÍCÍCH MEZERY
- kontigy často obsahují sekvence, které jsou poměrně jedinečné, protože REPETITIVNÍ SEKVENCE JSOU V SESTAVĚ DE NOVO ČASTO „MASKOVÁNY“ KVŮLI PROBLÉMŮM, KTERÉ ZPŮSOBUJÍ
- výsledkem je, že kontigy často končí nebo jsou od sebe odděleny CHYBĚJÍCÍMI OPAKUJÍCÍMI SE OBLASTMI, KTERÉ NEBYLY VYUŽITY (byly např. maskovány) NEBO JE NEBYLO MOŽNÉ BĚHEM SESTAVOVÁNÍ VYŘEŠIT
- s variacemi nalezenými na koncích kontigů je třeba zacházet opatrně
- některé systémy také vytvářejí superkontig, který spojuje všechny „zbylé“ kontigy, často nazývaný „superkontig 0“, ale pořadí a orientace těchto kontigů SE JEJICH BIOLOGICKÉMU UMÍSTĚNÍ NIJAK NEPODOBAJÍ
- každý způsob sestavování sekvencí OBSAHUJE ŘADU PROBLÉMŮ a většina projektů sekvenování genomu produkuje soubor zbylých čtení a kontigů, KTERÉ NEJSOU K SESTAVENÍ POUŽITY
- v některých případech mohou být tato čtení idetifikována jako:
- KONTAMINACE
- NEOČEKÁVANÝ SYMBIONT
- SEKVENCE GENOMU ORGANEL
- INDIKÁTOR KONKRÉTNÍCH DRUHŮ CHYB PŘI SESTAVOVÁNÍ
- NEOČEKÁVANÉ VARIACE SEKVENCE GENOMU, NAPŘ. VARIABILITA POČTU KOPIÍ NEBO VYSOKÁ ÚROVEŇ HETEROZYGOTNOSTI mezi alelami (zejména pokud byla sekvenována populace, nikoli jedinec)
- sestavené sekvence genomu lze také „vyleštit“
- „leštění“ je však VELMI ZÁVISLÉ NA VÝKONNOSTI ALIGNERU a koncový uživatel si musí být vědom toho, že opravené a vyleštěné sekvence budou představovat nejhojnější alely přítomné ve čteních
- jinými slovy, isoformy a vzácné varianty repetitivních sekvencí budou „OPRAVENY“, tj, PŘEPSÁNY při konečném sestavování hojnějšími sekvenačními variantami
- genové predikce jsou ZÁVISLÉ NA SESTAVENÍ GENOMU, což znamená, že pokud daná oblast chybí, nelze ji anotovat
- POKUD JE OBLAST ŠPATNĚ SESTAVENÁ NEBO CHYBÍ V SEKVENCI REFERENČNÍHO GENOMU POUŽITÉHO PRO ORTOLOGY, MŮŽE SE STÁT, ŽE BUDE CHYBĚT V SEKVENCI GENOMU, KTERÁ JE ANOTOVÁNA
- vzhledem k tomu, že U MNOHA PATOGENŮ NEEXISTUJÍ GENETICKÉ SYSTÉMY, KTERÉ MOHOU BÝT POUŽITY K VYTVOŘENÍ FYZICKÉ MAPY, je referenční mapování užitečné, ALE JE SNADNÉ ZAPOMENOUT NA PŮVOD SESTAV GENOMOVÝCH SEKVENCÍ A ANOTACÍ VYTVOŘENÝCH NEBO ŠÍŘENÝCH TÍMTO ZPŮSOBEM, proto je potřeba při používání sestav mapovaných podle referenčního genomu jako základu pro experimenty postupovat opatrně
- v závislosti na technologii, použité k vytvoření genomové sekvence, MOHOU BÝT TÉMĚŘ IDENTICKÉ KOPIE GENŮ SESTAVENY JAKO JEDEN GEN (k tomuto problému jsou nejčastěji náchylné sestavy s krátkým čtením)
- mírně odlišní členové genové rodiny, zvláště pokud jsou v tandemových opakováních, SE ČASTO NESESTAVÍ A LZE JE NAJÍT VE ZBYLÝCH ČTENÍCH NEBO MALÝCH NESESTAVENÝCH KONTIZÍCH
- NA ZÁKLADĚ STÁVAJÍCÍ ANOTACE JE SNADNÉ SE MYLNĚ DOMNÍVAT, že gen chybí
- geny se mohou ztratit a rozpadnout se nebo se změnit k nepoznání, ALE MOHOU TAKÉ CHYBĚT Z DŮVODU MEZERY V SESTAVENÉ SEKVENCI
- CHYBNÁ SESTAVENÍ A MEZERY MOHOU VYVOLÁVAT DOJEM CHYBĚJÍCÍCH GENŮ, ale ve skutečnosti V SESTAVĚ CHYBÍ, vyvinuly se do pseudo-genů nebo v některých případech byly nahrazeny horizontálním přenosem genů umístěných jinde v genomu
- mezery v sekvencích genomu mají mnoho dalších důsledků:
- Počet genů MŮŽE BÝT SNÍŽEN ve srovnání se skutečným počtem a ironií je, že počet genů MŮŽE BÝT TAKÉ ZVÝŠEN, protože část stejného genu lze nalézt na každé straně mezery, COŽ MÁ ZA NÁSLEDEK DVĚ DÍLČÍ PREDIKCE
- Malé mezery v sestavě často vedou k posunům rámců v kódovacích sekvencích, což zase VEDE K UMĚLÉMU NÁRŮSTU POČTU PSEUDO-GENŮ, přičemž ve skutečnosti je na vině mezera v sestavě
- Mezery mohou také indikovat umístění chybějící tandemové oblasti genů nebo opakujících se sekvencí, které NEBYLO MOŽNÉ SPRÁVNĚ SESTAVIT
- ANOTÁTORY NEMOHOU ANOTOVAT TO, CO NEEXISTUJE (např. MEZERY)
- nepřekládané oblasti a nekódující RNA nejsou běžně anotovány
- Zvláště důležitý je tento výrok:
- „VŠECHNY GENOMOVÉ SEKVENCE A JEJICH ANOTACE JSOU ‚VE STÁDIU VÝVOJE‘ A JSOU STATICKÝMI PŘEDSTAVITELI JEDNOHO ČASOVÉHO OKAMŽIKU NEUSTÁLE SE VYVÍJEJÍCÍ MOLEKULY V RÁMCI GENETICKY ROZMANITÉ POPULACE.“
- chyby v anotaci nebo chyby v sestavě mohou ovlivnit také analýzy drah
- velký podíl genů NEZNÁMÉ FUNKCE (u některých organismů až 40 %) kóduje funkce, které umožňují organismu vyřazení obejít
- jinými slovy, pokud lék nefunguje tak, jak se očekávalo, a vědci nechtějí svádět vinu na sestavu genomu, mohou místo toho vinit neznámé funkce určitých genů
- některé sekvence genomu již byly těmito novými technologiemi „OPRAVENY“, ALE STÁLE JE ZAPOTŘEBÍ ZNAČNÉ PRÁCE, ABY BYLY TAK DOBRÉ, JAK JE TO JEN MOŽNÉ
Někteří odborníci z článku molekulárního biologa Ulricha Bahnsena z roku 2008 o neustále se měnících genomech uvedli:
„Genom byl považován za neměnný plán lidské bytosti, který je určen na počátku našeho života. VĚDA SE MUSÍ S TOUTO MYŠLENKOU ROZLOUČIT. VE SKUTEČNOSTI JE NAŠE GENETICKÁ VÝBAVA VE STAVU NEUSTÁLÝCH ZMĚN.“
„Experti věřili, že porozuměli tomu, jak gen vypadá a jak funguje, podle jakých funkčních principů se lidský nebo mikrobiální genom řídí. ‚ZPĚTNĚ VIDĚNO, NAŠE TEHDEJŠÍ DOMNĚNKY O TOM, JAK GENOM FUNGUJE, BYLY TAK NAIVNÍ, ŽE JE TO AŽ TRAPNÉ,‘ uvedl Craig Venter, který se na projektu podílel se svou společností Celera.“
„Do té doby SE PŘEDPOKLÁDALO, ŽE GENETICKÝ MATERIÁL JAKÝCHKOLI DVOU LIDÍ SE LIŠÍ JEN ASI JEDNÍM PROMILE VŠECH STAVEBNÍCH BLOKŮ DNA. Ale rozdíly v genetické výbavě lidí jsou ve skutečnosti tak velké, že věda nyní potvrzuje to, co lidový jazyk již dávno ví: KAŽDÝ ČLOVĚK JE JINÝ. ÚPLNĚ JINÝ!“
„MYŠLENKA, ŽE GENOM PŘEDSTAVUJE PŘIROZENOU KONSTANTU, PEVNÝ ZDROJOVÝ KÓD LIDSKÉ BYTOSTI, SE NYNÍ POD TÍHOU NÁLEZŮ HROUTÍ. Americký genetik Matthew Hahn již dříve přirovnal genom k otočným dveřím: ‚GENY NEUSTÁLE PŘICHÁZEJÍ, ZATÍMCO JINÉ ODCHÁZEJÍ.‘ “
https://telegra.ph/Genetics-Genome-in-Dissolution-11-01
Jak spolehlivé a přesné, po přečtení dlouhého seznamu problémů spojených s tvorbou genomů a rozboru domněnek o statickém genomu, podle vás tyto „PRÁCE VE STÁDIU VÝVOJE“ skutečně jsou?
- Krize reprodukovatelnosti v genomice:
- Problémy s referenčními genomy:
- Problémy s „virovou“ genomikou:
- Problémy s genomy „SARS-CoV-2“:



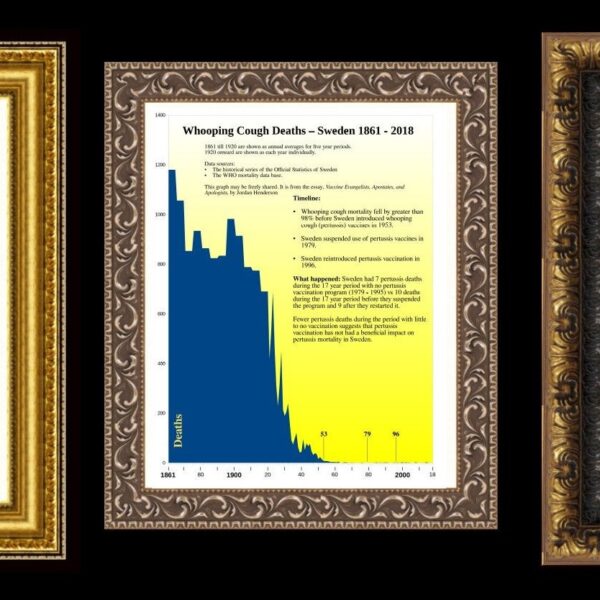

Je vidět, že článek psal někdo, kdo se v problematice vyzná. Skutečně je mylná představa , že genom je nejaky neměnný archiv. Stejně tak je mylně se domnívat, že genomy složitějších organismu budou někdy precteny do poslední báze. Ale uniká mi souvislost s genovou sekvencí víru, které jsou neskonale kratší, jednodušší, bez repetic, duplikaci, pseudogenu, retrotranspozonu a dalšího smetí.U sekvenovani víru představují problém pouze prvních a posledních 20 bázi u víru s lineárním genomem a SNP mutace související s vysokou rychlostí evoluce, zejména u RNA víru. V článku popisujete požadavek na to, aby byla sekvence přečtená aspoň 10x a dál se tak odfiltrovat šum. Sekvence SCV2 jsou čteny 1000x, výjimkou není pokrytí sekvence 50.000x. To už přesnější nebude. A takových sekvencí jsou v gisaid přes 3 miliony.
Článek se týká reálně existujících organismů, z kterých se dá genom číst. Článek poukazuje na technologické problémy s jejich přesným čtením a v té spojitosti s vytvářením diagnostických či jakýchkoliv jiných závěrů na základě těchto nepřesných čtení.
Z Vašeho komentáře lze vyvodit, že předpokládáte několik věcí. Za prvé, reálnou existenci jakéhokoli živočišného patogenního „viru“. To musí být stále prokázáno, protože žádný živočišný „virus“ nebyl nikdy řádně vyčištěn/izolován přímo od nemocného pacienta a prokázán jako patogenní. Druhým Vaším předpokladem je, že „viry“ mutují nebo se vyvíjejí. Je to teoretické, to se nedá pozorovat. Mutace a evoluce se používají k zakrytí skutečnosti, že bio-informatici nejsou schopni sekvenovat stejnou věc (pokud by ji skutečně měli) dvakrát. Skutečnost, že v současné době existuje více než 3,5 milionu genomů „SARS-COV-2“, by to měla dostatečně objasnit. Aby byl jakýkoli genom považován za platný, musí se nejprve prokázat, že věc, z níž je získán, fyzicky existuje. To se u živočišných virů nikdy nestalo. Jediné, co bio-informatici mají, jsou náhodná A, C, T, G sestavená počítačovými algoritmy založenými na shodě alignementu a referenčních genomech vytvořených stejnými metodami.